Understanding how Puma handles requests

April 23, 2025
This is Part 1 of our blog series on scaling Rails applications.
If we do rails new to create a new Rails
application, Puma will be the default web server. Let's start
by explaining how Puma handles requests.
How does Puma handle requests?
Puma listens to incoming requests on a TCP socket. When a request comes in, then that request is queued up in the socket. The request is then picked up by a Puma process. In Puma, a process is a separate OS process that runs an instance of the Rails application.
Note that Puma official documentation calls a Puma process a Puma worker. Since the term "worker" might confuse people with background workers like Sidekiq or SolidQueue, in this article, we have used the word Puma process at a few places to remove any ambiguity.
Now, let's look at how a request is processed by Puma step-by-step.
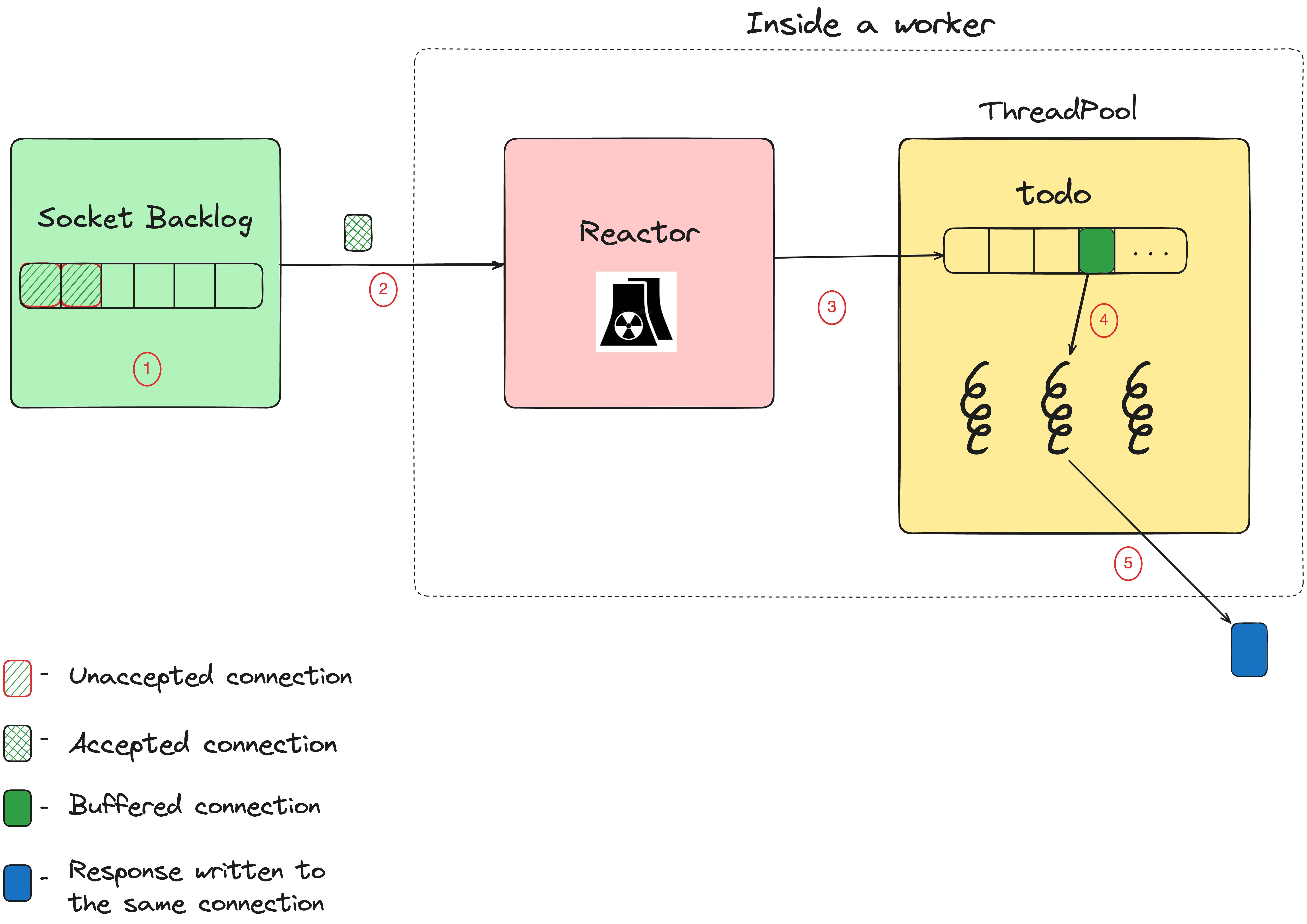
-
All the incoming connections are added to the socket backlog, which is an OS level queue that holds pending connections.
-
A separate thread (created by the Reactor class) reads the connection from the socket backlog. As the name suggests, this Reactor class implements the reactor pattern. The reactor can manage multiple connections at a time thanks to non-blocking I/O and an event-driven architecture.
-
Once the incoming request is fully buffered in memory, the request is passed to the thread pool where the request resides in the
@todoarray. -
A thread in the thread pool pulls a request from the
@todoarray and processes it. The thread calls the Rack application, which, in our case is a Rails application, and generates a response. -
The response is then sent back to the client via the same connection. Once this is complete, the thread is released back to the thread pool to handle the next item from the
@todoarray.
Modes in Puma
-
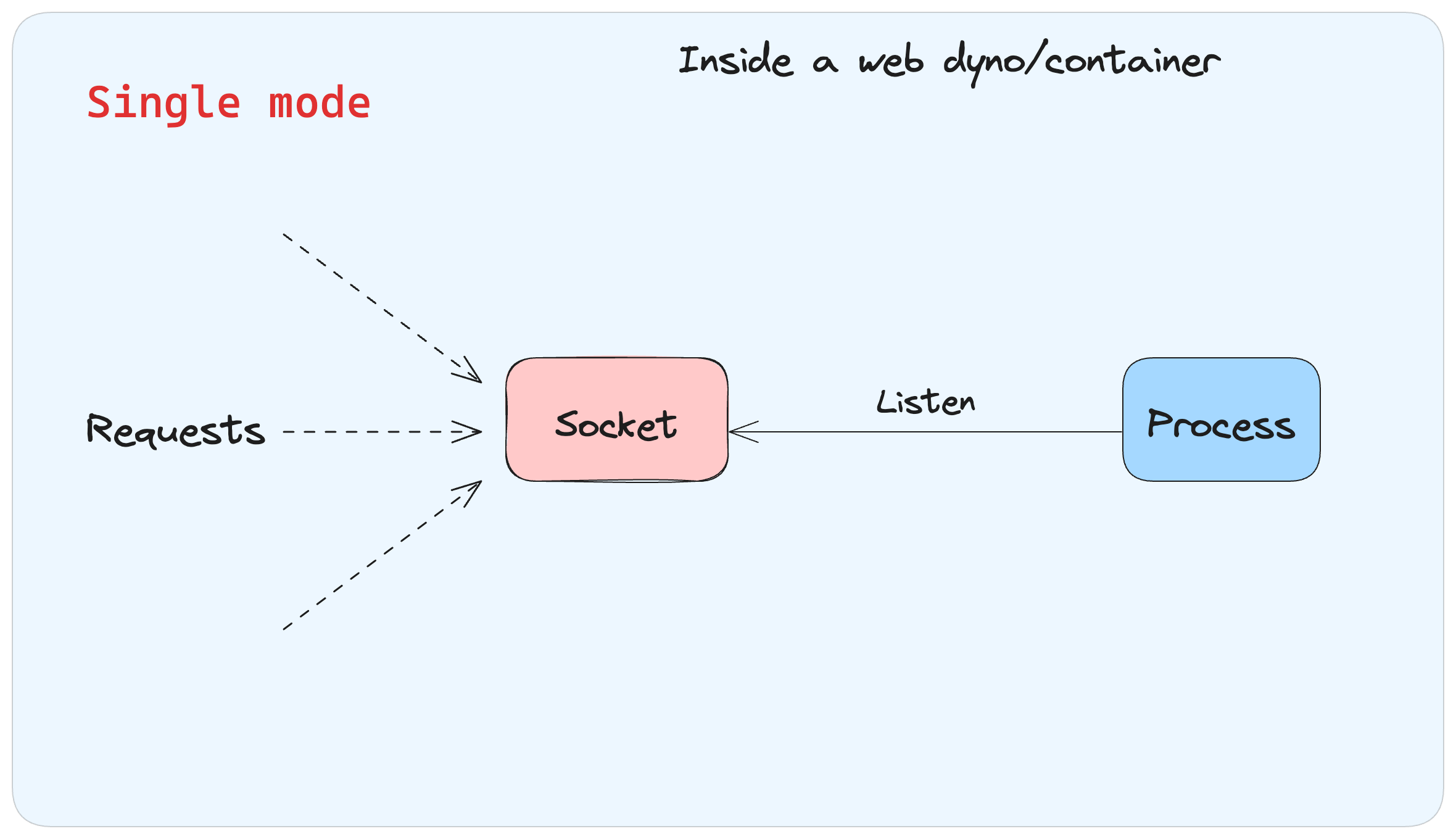
Single Mode: In single mode, only a single Puma process boots and does not have any additional child processes. It is suitable only for applications with low traffic.
-
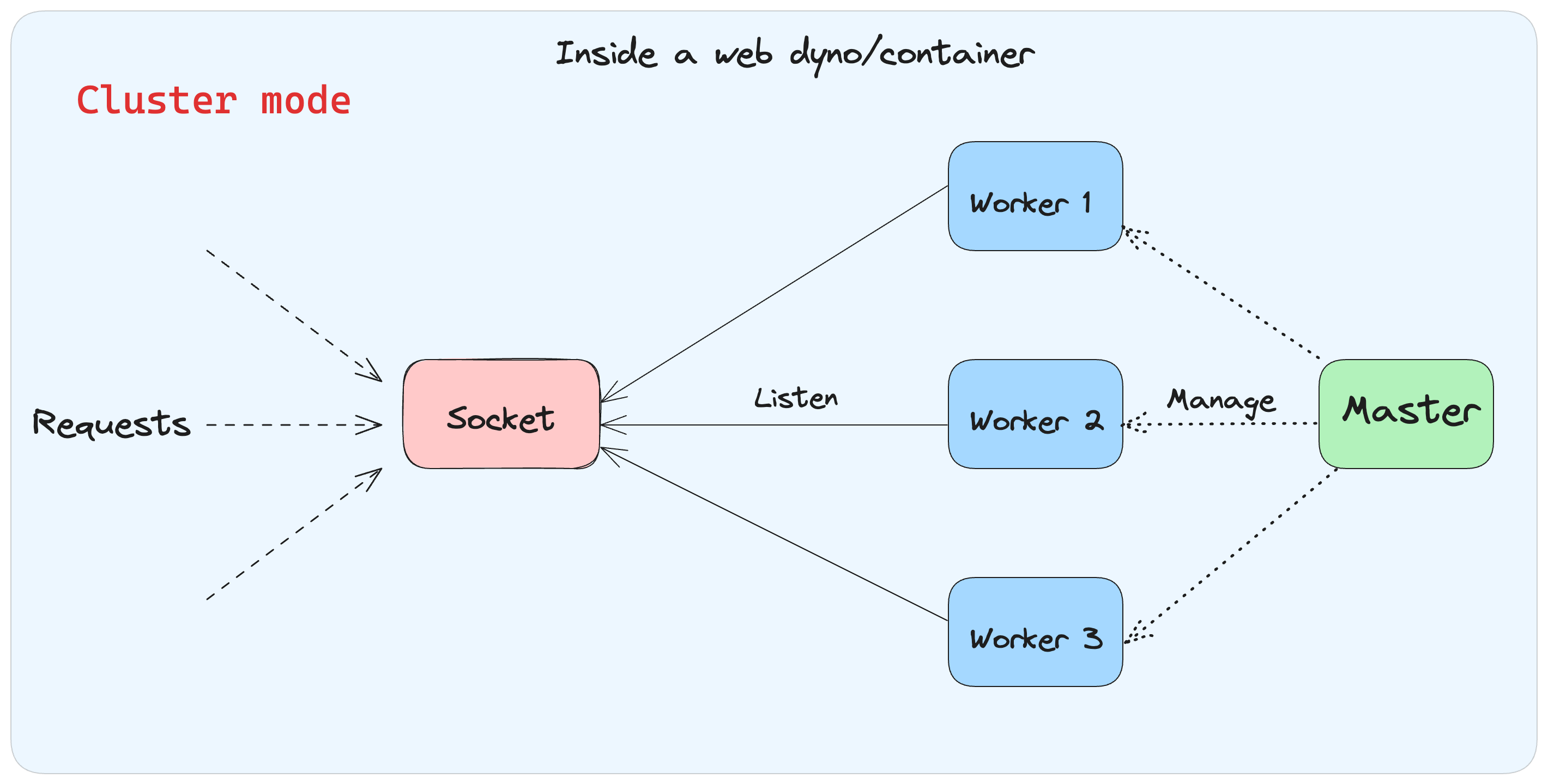
Cluster Mode: In cluster mode, Puma boots up a master process, which prepares the application and then invokes the fork() system call to create one or more child processes. These processes are the ones that are responsible for handling requests. The master process monitors and manages these child processes.
Default Puma configuration in a new Rails application
When we create a new Rails 8 or higher application, the default Puma
config/puma.rb will have the following code.
Please note that we are mentioning Rails 8 here because the Puma configuration is different in prior versions of Rails.
threads_count = ENV.fetch("RAILS_MAX_THREADS", 3)
threads threads_count, threads_count
rails_env = ENV.fetch("RAILS_ENV", "development")
environment rails_env
case rails_env
when "production"
workers_count = Integer(ENV.fetch("WEB_CONCURRENCY", 1))
workers workers_count if workers_count > 1
preload_app!
when "development"
worker_timeout 3600
end
For a brand new Rails application, the env variables RAILS_MAX_THREADS and
WEB_CONCURRENCY won't be set. This means threads_count will be set to 3 and
workers_count will be 1.
Now let's look at the second line from the above mentioned code.
threads threads_count, threads_count
In the above code, threads is a method to which we are passing two arguments.
The default value of threads_count is 3. So effectively, we are calling method
threads like this.
threads(3, 3)
The threads method in Puma takes two arguments: min and max. These arguments
specify the minimum and maximum number of threads that each Puma process will
use to handle requests. In this case Puma will initialize 3 threads in the
thread pool.
Now let's look at the following line from the above mentioned code.
workers workers_count if workers_count > 1
The value of workers_count in this case is 1, so Puma will run in single
mode. As mentioned earlier in Puma a worker is basically a process. It's not
background job worker.
What we have seen is that if we don't specify RAILS_MAX_THREADS or
WEB_CONCURRENCY then, by default, Puma will boot a single process and that
process will have three threads. In other words Rails will boot with the ability
to handle 3 requests concurrently.
This is the default value for Puma for Rails booting in development or in production mode - a single process with three threads.
Configuring Puma's concurrency and parallelism
When it comes to concurrency and parallelism in Puma, there are two primary parameters we can configure: the number of threads each process will have and the number of processes we need.
To figure out the right value for each of these parameters, we need to know how Ruby works. Specifically, we need to know how GVL in Ruby works and how it impacts the performance of Rails applications.
We also need to know what kind of Rails application it is. Is it a CPU intensive application, IO intensive or somewhere in between.
Don't worry in the next blog, we will start from the basics and will discuss all this and much more.
This was Part 1 of our blog series on scaling Rails applications. If any part of the blog is not clear to you then please write to us at LinkedIn, Twitter or BigBinary website.
Follow @bigbinary on X. Check out our full blog archive.